データフローダイアグラムの書き方
はじめに
これまで作成したデータモデルをもとに,「アプリケーションルール」の作成を行います.「アプリケーションルール」を以下のように定義します.
- アプリケーションルール
- エンティティのデータや他のプロセスの出力結果を使い,業務上必要な情報を導き出す方法.
データモデルからアプリケーションルールを作るのですから,アプリケーションルールはデータモデルに「依存」します.これに対し,アプリケーションルールはユーザインターフェースからは「独立」します.すなわち,ユーザインタフェースが未定義のままでもアプリケーションルールの設計は可能です.今回も,ユーザインタフェースは未定義です.これは,画面や帳票のレイアウトや操作方法の変更がアプリケーションルールに影響を与えないことを表しています.
アプリケーションルールを表す手段としてデータフローダイヤグラム(以下DFDと略記)を使用します.その理由は,データ構造とそれらを操作するプログラムのカプセル化やモジュールの独立性の確保という考え方が,DFDを使用したほうが解りやすいからです.具体的な記述はまた別の機会に.
データフローダイアグラムの書き方
シンボルの説明
今回は,以下にあげたシンボルを使用してDFDを作成します.
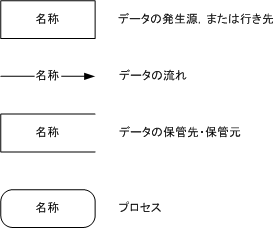 |
プロセスには入力と出力が存在する
プロセスには入力と出力が必ず存在します.入力だけ,出力だけのプロセスは存在しません.
 |
データの流れを書く
DFDはその名前の示す通り,「データの流れ」を図にしたものです.これに対し,流れ図(フローチャート)や各種構造化チャートは「実行順番や制御順序」を図にしたものです.この相違点をはっきりと認識しなければ,役に立つDFDは作成できません.例えば,次のように3プロセスを順番に実行するプログラムを考えます.
- 保管元Aからデータaを受け取りデータbを出力するプロセス1を実行.
- 保管元Aデータaを受け取りデータcを出力するプロセス2を実行.
- プロセス1の出力データbとプロセス2の出力データcを受け取りデータdを出力するプロセス3を実行.保管先Bに保管.
これを流れ図で表すと下図のようになります.プロセス1,2,3を順番に実行していく簡単なものです.
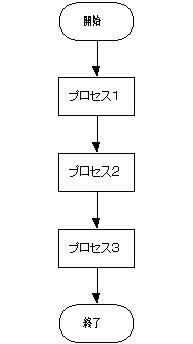 |
この流れ図の矢印は実行するプロセスの実行順番・制御順序を表しています.各々のプロセスへの入力,プロセスからの出力は対象とはしていません.
同じプログラムをDFDで表現します.この時気をつけなければならないのは,下図のようにプロセスの実行順番・制御順序を書いてしまうことです.
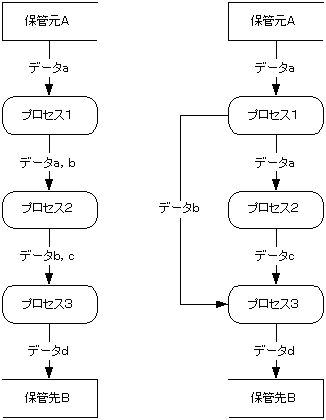 |
このプログラムのDFDは下図のようになります.
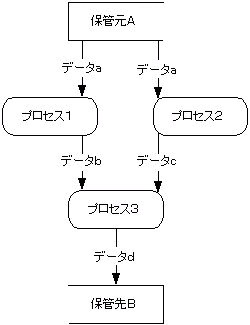 |
違いを検討します.図4の場合,「プロセス1,2,3の順番で実行しなければならない」という思い込みの結果,データの流れを表すはずの矢印が「プロセスのの実行順番・制御順序」を表しています.
確かに,プロセス1,2,3の順番で箇条書きになっていますが,プロセス2はプロセス1の終了後でなくても実行可能です.つまり,プロセス2はデータaがあれば実行可能で,プロセス1からは何の影響も受けていません.したがって,プロセス2はプロセス1の次に実行しなくてはならないものではなく,プロセス1とは独立してデータ源Aからデータaを受け取り,実行できるのです.それに対して,プロセス3の実行にはプロセス1の出力であるデータbとプロセス2の出力であるデータcが必要です.
また,DFDで「プログラムの処理の流れ,制御方向,実行順序」を描くと機能の入出力データに不要なものが多発します.プロセス1の出力は本来データbのみです.しかし,図4では「プロセス1の後に実行しなければならないプロセス2」の入力データを確保するため,入力値データaも出力しています.
流れ図とDFDの優劣の問題ではありません.流れ図はプロセスの実行順番・制御順序を表現するために描き,DFDはデータの流れを表現するために描きます.表現するものが違うのですから,出来上がりが違うのは当然です.ここで問題にしているのは,流れ図が表現しようとしている「実行順番・制御順序」をDFDで描いてはならない,ということです.
名前を付ける
DFDに存在する要素(データの発生源・行き先,データの流れ,データの保管先・保管元,プロセス)には,それぞれ名前が必要です.その際,以下の原則を厳守しなければなりません.
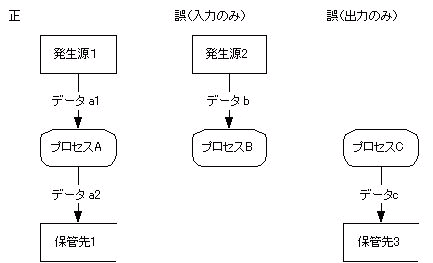
プロセスは最後に名前をつける.すなわち,データの流れ,データの発生源・行き先,データの保管元・保管先全てに名前がつくまで,プロセスには名前をつけない.
プロセス,データの発生源・行き先,データの保管元・保管先全てに名前がついているにもかかわらず,データの流れにだけ名前がついていないDFDを見かけることがあります.これらはDFDの役割を果たしていません.DFDが表現しなければならないのは,プロセス,データの発生源・行き先,データの保管元・保管先を行き来するデータなのです.データの流れに名前をつけないのは,DFDが最も表現しなければならないものを表現していないということです.
機能に名前がないとわけか分からなくなると思うかも知れません.しかし,出入りするデータからプロセスの内容は推測は容易です.逆に,プロセスからの入出力データの推測は困難です.(下図参照).
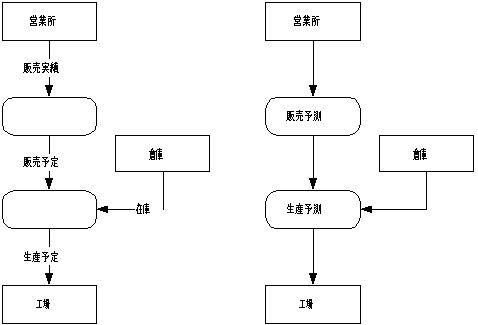 |
入出力するデータからプロセスの内容の推測が困難な場合,原因はプロセスの機能分割が適切ではないことが多々あります.プロセスは,例え名前がなくても,入出力データからその内容を容易に推測できるものでなくてはなりません.
データの流れに名前をつける際には,「~情報」や「~データ」と言う名前をつけてはいけません.抽象的すぎ何を表わしているのかわかりません.図6の営業所からのデータの流れの名前が「販売実績」ではなく「営業所情報」や「販売情報」だったら,何を表わしているのかわかるでしょうか.もし,データの流れに具体的な名前がつけられないのなら,DFDの作り方に間違いがあります.再検討しましょう.
データの流れと同様にプロセスにも具体的な名前をつけなければなりません.「~処理」や「~機能」という何をやっているのかわからない名前をつけてはいけません.図6のプロセスの名前「販売予測」ではなく「販売実績処理」や「販売機能」だったら何を表わしているのかわかるでしょうか.もし,プロセスに具体的な名前がつけられないのなら,DFDの作り方に間違いがあります.再検討しましょう.
まとめ
- アプリケーションルールはデータモデルに依存するがユーザインタフェースからは独立する.
- DFDの矢印はデータの流れ.実行順番ではない.
- プロセスには入力と出力が存在する.
- プロセスの名前は最後につける.データの発生源・行き先,データの流れ,データの保管先・保管元全てにまず名前をつける.
- 「~情報・~データ・~処理・~機能」といった抽像的な名前は厳禁.
参考文献
Tom DeMarco "Structured Analysis and System Specification" 1979
(高梨智弘,黒田純一郎監訳 "構造化分析とシステム仕様" 日経BP出版センター)
Audrey M. Weaver "USING THE STRUCTUAED TECHNIQUES A Case Study" Prentice-Hall, Inc. 1987
(神間清展訳 "構造化技法を使いこなす" 総研出版 1989)
Arthur Young Information Technology Group "The Arthur Young practical guide to information engineering" Arthur Young & Company 1987
(高梨智弘,竹本則彦訳 "管理職のためのインフォメーションエンジニアリング" 日経BP社)
岡田英明 "システム部門再生講座" 戦略コンピュータ 1994年10月号 Vol.33 No.10 p.50- 日刊工業新聞社